What Happens to RAG Systems in Production Over Time
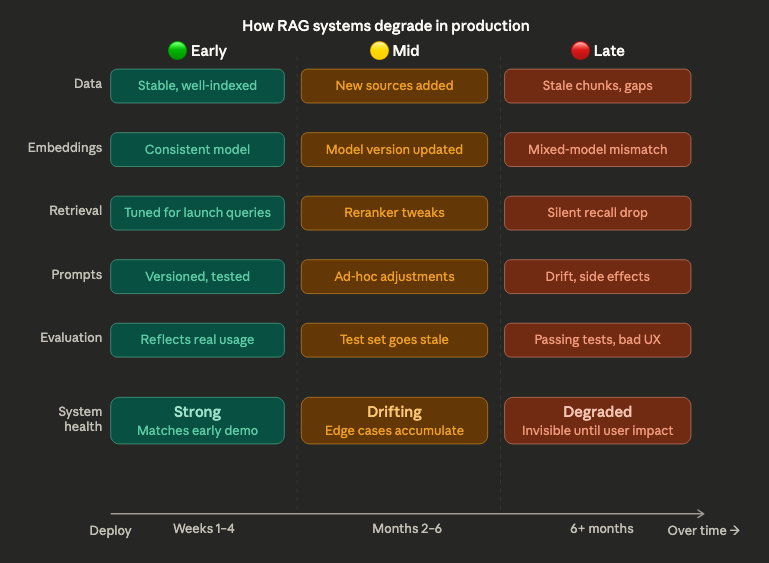
RAG systems often start strong. Early demos look promising, responses feel relevant, and initial evaluations show solid performance. But over time, something changes. Answers become less consistent, retrieval quality drifts, and edge cases appear more frequently. The system hasn’t been “broken” — but it’s no longer behaving the way it did at the start. This gradual decline is one of the most common and least discussed challenges in production AI systems.
The reason is that RAG systems are not static. They depend on components that evolve continuously: data sources are updated, embeddings change, ranking behavior shifts, and user queries become more diverse. Each of these changes introduces variability. On its own, each layer may seem manageable. But together, they create a system that behaves differently over time, even if no single change appears significant. What teams experience as degradation is often the result of accumulated, untracked change.
How RAG systems degrade in production
Another factor is that evaluation does not keep pace with the system. Many teams rely on fixed datasets or periodic testing, which quickly becomes outdated as the system evolves. A RAG pipeline can pass evaluation while silently drifting in production. Retrieval quality may decline for certain query types, or newer data may introduce inconsistencies that aren’t captured in test cases. Without continuous evaluation tied to real usage, degradation remains invisible until it impacts users.
There is also a structural challenge: RAG systems optimize locally but degrade globally. Improvements in one component — for example, updating embeddings or tuning prompts — can unintentionally affect other parts of the system. Better retrieval recall might introduce more noise. Prompt adjustments might change how sources are used. These interactions are difficult to predict, especially without visibility into how the system behaves end-to-end. Over time, small optimizations can accumulate into system-level instability.
Addressing this requires a shift in how RAG systems are operated. Instead of treating them as deploy-and-monitor systems, teams need to think in terms of continuous calibration. This means integrating evaluation with observability, tracking how retrieval, prompts, and outputs evolve over time, and establishing feedback loops that reflect real-world usage. Degradation is not an anomaly — it is an expected property of systems built on changing data and probabilistic components.
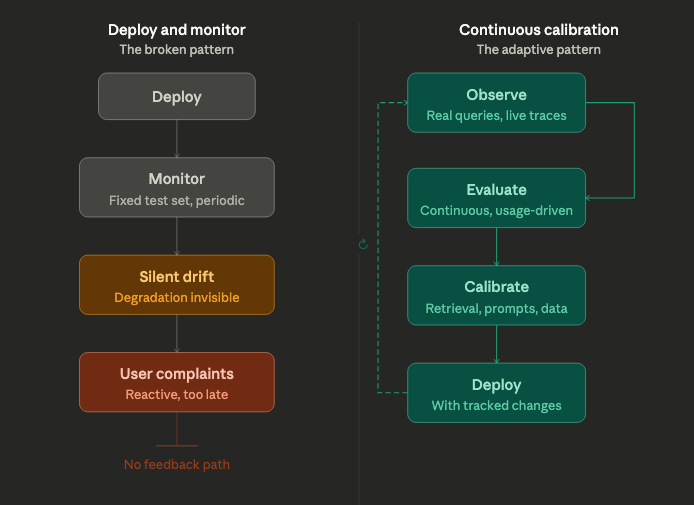
Continuous Calibration
RAG systems don’t degrade because they are poorly built. They degrade because they are dynamic. The challenge is not to prevent change, but to make it visible, measurable, and manageable. Teams that recognize this early can design systems that adapt over time. Those that don’t often find themselves chasing issues that are difficult to trace and even harder to fix.