Using AI to Optimize an Agentic RAG Platform: Why Local Validation Still Matters
In my previous articles, I explored how observability supports AI security, governance, and compliance. While continuing development of my Agentic RAG platform, I found myself applying many of those same principles during development. This time, however, the focus wasn't on production observability—it was on improving the engineering feedback loop itself.
The feature I was working on was my Evaluation pipeline. As I expanded evaluation capabilities, latency became the biggest obstacle to rapid iteration. Faster evaluations meant faster experimentation, shorter development cycles, and more opportunities to validate improvements before moving on to the next feature.
Rather than treating AI as an automatic code generator, I approached it as an engineering collaborator. I asked it to analyze bottlenecks, suggest targeted optimizations, explain the reasoning behind each recommendation, and propose alternatives where appropriate. The quality of the suggestions was impressive. Several changes significantly reduced latency, simplified portions of the implementation, and improved the overall responsiveness of the evaluation workflow. Two images below show latency before and after improvements.


The biggest lesson, however, wasn't about AI's ability to optimize code—it was about the importance of validating every optimization locally.
At a recent Codex Meetup in San Francisco, I had an interesting conversation with an engineer from Reddit. During our discussion, he mentioned that he didn't have a local environment for validating AI-generated changes before committing them. That conversation stayed with me because my experience had been quite different. Several optimizations suggested by AI appeared perfectly reasonable during review, but only local execution revealed whether they actually delivered the expected improvements. In a few cases, I discovered regressions, subtle behavioral differences, or optimizations that simply didn't produce meaningful performance gains. Those findings would have been difficult to identify through code review alone.
That experience gradually evolved into a repeatable engineering workflow. Every optimization began with measuring the existing bottleneck, followed by targeted AI-assisted suggestions, incremental implementation, local validation, latency benchmarking, and a full evaluation run before any code was committed. The AI dramatically accelerated the optimization process, but measurement and validation remained essential parts of the engineering discipline.
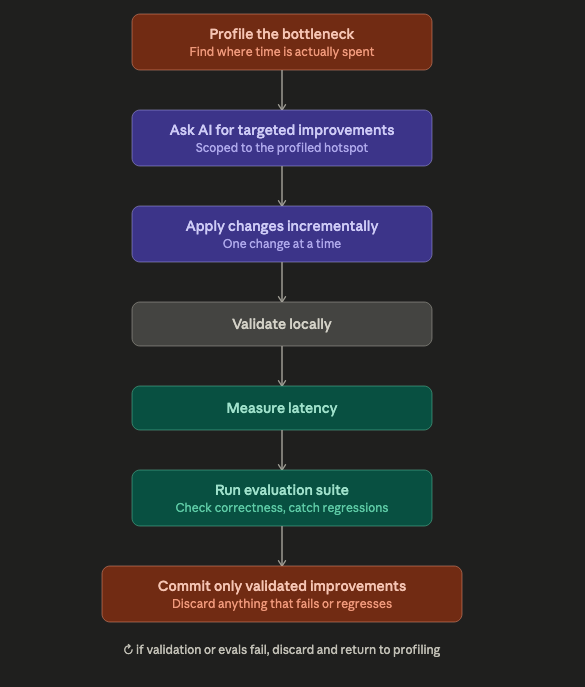
Human-Validated AI Development Cycle
One unexpected realization was how closely this mirrors the principles behind AI observability. In production, we rely on traces, evaluations, and monitoring to verify how AI systems behave under real workloads. During development, local validation serves a similar purpose—it provides objective evidence that a proposed change actually improves the system rather than simply appearing to do so. Whether validating an LLM response or an AI-generated code change, evidence consistently proves more valuable than assumptions.
This experience reinforced an important lesson for me: AI coding assistants are becoming exceptional implementation partners, but they don't eliminate the need for engineering rigor. They generate ideas, accelerate experimentation, and often uncover optimizations that might otherwise be overlooked. It is still the responsibility of the engineer to measure, validate, benchmark, and confirm that those improvements hold up in practice.
As AI becomes a regular part of software development, I believe the most effective teams won't be those that rely on AI the most—they'll be the ones that build disciplined workflows around it. In my experience, combining AI-assisted development with local validation, repeatable measurements, and continuous evaluation produces far better outcomes than either approach alone.
When Observability Stops Being a Tool Choice and Becomes an Architecture Choice
In my previous article, When AI Observability Becomes Compliance Infrastructure, I argued that observability is evolving from a debugging capability into a foundational requirement for governance, auditability, and trust.
Recently, I instrumented the same Agentic RAG application with both LangSmith and Langfuse to better understand what observability looks like in practice.
The goal was not to determine which platform is "better."
The goal was to understand how different observability approaches shape the way we operate AI systems.
What I discovered is that the most important difference between observability platforms is not their dashboards, user interfaces, or individual features.
The most important difference is what role observability plays in the overall architecture.
The Same System, Two Observability Models
The application itself remained unchanged.
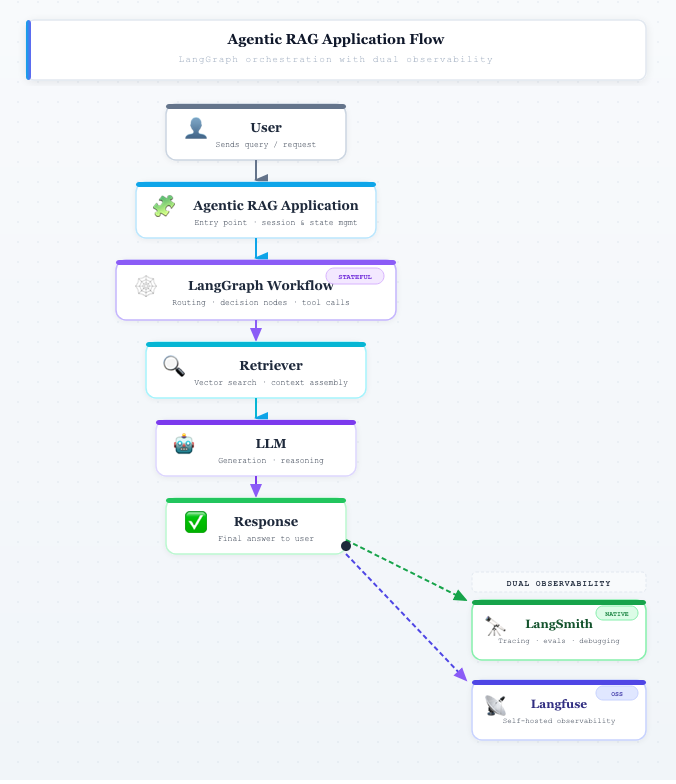
The LangGraph node has a "stateful" badge to highlight its role in agentic orchestration
The same workflows executed.
The same prompts were submitted.
The same retrieval pipeline operated.
The same model generated responses.
Both platforms observed the same underlying system.
Yet they encouraged slightly different ways of thinking about observability.
One emphasized developer productivity and rapid debugging.
The other emphasized ownership, flexibility, and operational control.
Both perspectives proved valuable.
What LangSmith Does Exceptionally Well
The first thing that stood out was how quickly LangSmith provided useful visibility into the system.
Key strengths include:
Fast setup
Excellent workflow visualization
Strong LangChain and LangGraph integration
Minimal configuration
Intuitive debugging experience
The trace views consistently made it easier to understand what happened inside a workflow and where failures occurred.
When investigating retrieval quality issues, prompt behavior, or agent execution paths, the ability to inspect individual steps significantly reduced troubleshooting time.
The overall experience feels optimized for helping developers understand system behavior as quickly as possible.
That is particularly valuable when building and iterating on complex AI workflows.
What Langfuse Does Differently
While Langfuse provides many of the same observability capabilities, the platform feels different in practice.
Several characteristics stood out:
Open-source architecture
Self-hosting capabilities
Data ownership
Export flexibility
Vendor independence
One observation that emerged during implementation was that Langfuse felt less like a service being consumed and more like infrastructure being operated.
That distinction may seem subtle initially, but it becomes increasingly relevant as AI systems move beyond experimentation and into environments with governance, compliance, or data residency requirements.
Questions begin to emerge that extend beyond debugging:
Where are observability records stored?
Who owns those records?
How long are they retained?
Can they be exported?
Can they remain within a particular jurisdiction?
Those questions are architectural rather than operational.
The Trade-Off That is Less Discussed
Many product comparisons focus on features.
My experience suggested a different comparison.
The most important trade-off is not interface versus interface.
It is convenience versus control.

Neither approach is inherently better.
The choice depends on what problem an organization is trying to solve.
Teams focused on rapid experimentation may prioritize simplicity and ease of adoption.
Organizations operating under stricter governance requirements may place greater value on ownership and deployment flexibility.
Both represent valid architectural choices.
What Changed My Thinking
Before implementing both platforms, I primarily viewed observability as a developer tool.
The objective was straightforward:
Understand failures faster
Improve debugging efficiency
Increase development velocity
After instrumenting the same system with both LangSmith and Langfuse, my perspective changed.
I began viewing observability as an architectural layer.
The question is no longer:
"Which interface do I prefer?"
The more interesting question is:
"Who owns the operational data generated by my AI system?"
That single question influences decisions around governance, compliance, security, retention, portability, and long-term operational strategy.
It also changes how observability fits into the overall system design.
Conclusion
One of the most interesting outcomes of implementing both platforms was realizing that observability is no longer a single capability.
Tracing remains important.
Debugging remains important.
Developer productivity remains important.
But as AI systems become more deeply integrated into business processes, observability begins serving additional purposes: governance, accountability, operational control, and trust.
LangSmith and Langfuse both provide valuable visibility into AI workflows.
What differs is not simply how they present information, but how they position observability within the architecture.
My initial goal was to compare two observability platforms.
The larger lesson was that observability is increasingly becoming an architectural decision.
As AI systems mature, organizations may find themselves spending less time asking which tool they prefer and more time asking what level of ownership and control they need over the operational data their systems generate.
When AI Observability Becomes Compliance Infrastructure
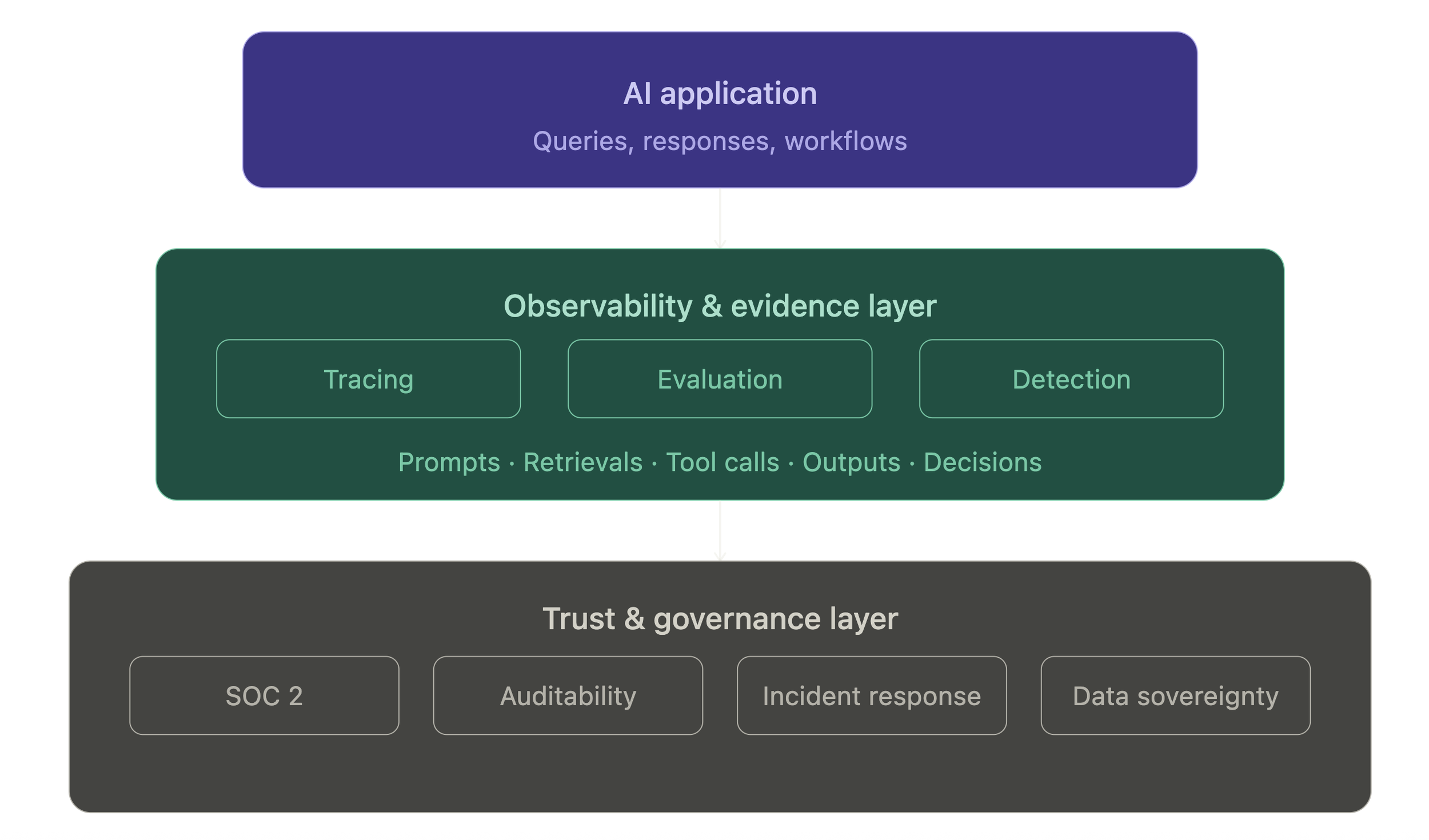
AI Trust Governance Layers
In many AI projects, observability starts as a developer tool. Teams implement tracing to debug prompts, evaluate retrieval quality, or understand why an agent made a particular decision. But as AI systems move into production, observability becomes something much bigger: part of the organization's compliance and governance architecture.
The reason is simple. AI traces often contain more than technical telemetry. They may include prompts, retrieved documents, tool invocations, customer data, business context, and decision paths. From a security and compliance perspective, these traces can become just as sensitive as the underlying application data.
This creates a new set of questions. Where does trace data live? Who controls retention policies? Can traces remain within a regulated environment? What happens if auditors request evidence of model behavior, prompt changes, or incident investigations? At that point, observability is no longer just an engineering concern—it becomes a governance concern.
For organizations operating in financial services, healthcare, government, defense, or other regulated industries, vendor independence and data sovereignty can become important architectural requirements. Self-hosted and open-source observability platforms such as Langfuse or Arize Phoenix are gaining attention not simply because they provide tracing, but because they allow organizations to maintain greater control over where operational AI data resides and how it is managed.
This feels similar to the evolution of traditional security logging. What began as troubleshooting eventually became a critical component of audit readiness, incident response, and regulatory compliance. AI observability appears to be following a similar path.
As organizations continue building AI-powered applications, the question may no longer be whether tracing is needed. The more interesting question may be: who owns the observability layer, and does it align with your security, compliance, and data sovereignty requirements?
Why LLM Tracing Is Becoming a SOC 2 Requirement for AI Systems
As LLM-powered applications move into production, organizations are discovering that traditional logging and monitoring are no longer sufficient to meet security and compliance expectations like SOC 2. Unlike deterministic systems, LLM applications introduce probabilistic behavior, dynamic tool execution, and external context injection through RAG and agents. This fundamentally changes what “auditability” means. Tracing systems like LangSmith are emerging as the missing layer that makes AI behavior observable, reviewable, and ultimately compliant.
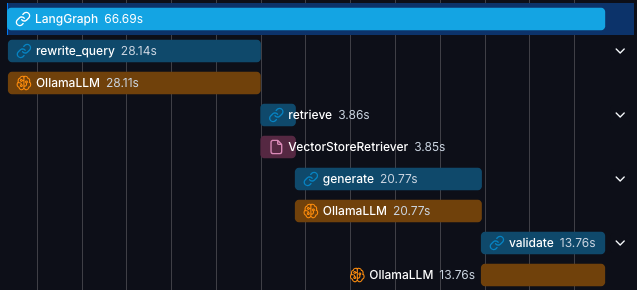
Traces details example
Be able to show every agent’s step
One of the clearest ways to understand this shift is through the lens of OWASP’s Top LLM vulnerabilities. For example, Prompt Injection remains one of the most critical risks, where malicious or untrusted inputs manipulate model behavior or override system instructions. Without tracing, it is nearly impossible to reconstruct how or where an injected instruction influenced downstream decisions. With full execution traces, teams can inspect the exact prompt chain, retrieved context, and tool calls to determine how the model was influenced — effectively turning an opaque attack surface into an auditable event stream.
A second major category is Sensitive Information Disclosure, where models unintentionally expose PII, secrets, or proprietary data through prompts, retrieved context, or generated outputs. In SOC 2 terms, this maps directly to data protection and access control requirements. Tracing provides end-to-end visibility into what data entered the system, how it was transformed, and where it was surfaced in outputs. This allows teams to prove not only that controls exist, but that they are consistently enforced across real-world interactions.
A third relevant risk is Excessive Agency / Over-Privileged Tool Use, where LLM agents can trigger external actions such as API calls, database updates, or workflow executions. In production systems, this becomes a critical security boundary problem. Tracing makes every tool invocation explicit and replayable, allowing teams to validate whether an action was expected, authorized, and aligned with system design. This is especially important for incident response and postmortems, where reconstructing the exact decision path is essential.
When viewed through these risks, LLM tracing becomes more than a debugging tool — it becomes a foundational compliance primitive. For SOC 2 and emerging SOC 3 expectations, organizations need demonstrable evidence of system behavior, not just static controls. Tracing provides that evidence layer by capturing execution-level truth across prompts, models, retrieval systems, and tools. In practice, this shifts AI systems from “black box outputs” to auditable, governable systems — which is exactly what modern security and compliance frameworks are beginning to require.
From RAG to Agentic RAG: Where ADK Fits (and Where It Doesn’t)
Retrieval-Augmented Generation (RAG) has quickly become a foundational pattern for building AI systems that ground responses in real data. And it works—up to a point. But anyone who has spent time building a RAG system knows where it starts to break down: vague user queries, incomplete retrieval, and no mechanism to recover when the first answer isn’t good enough. The limitation isn’t just the model or the data. It’s the lack of iteration.
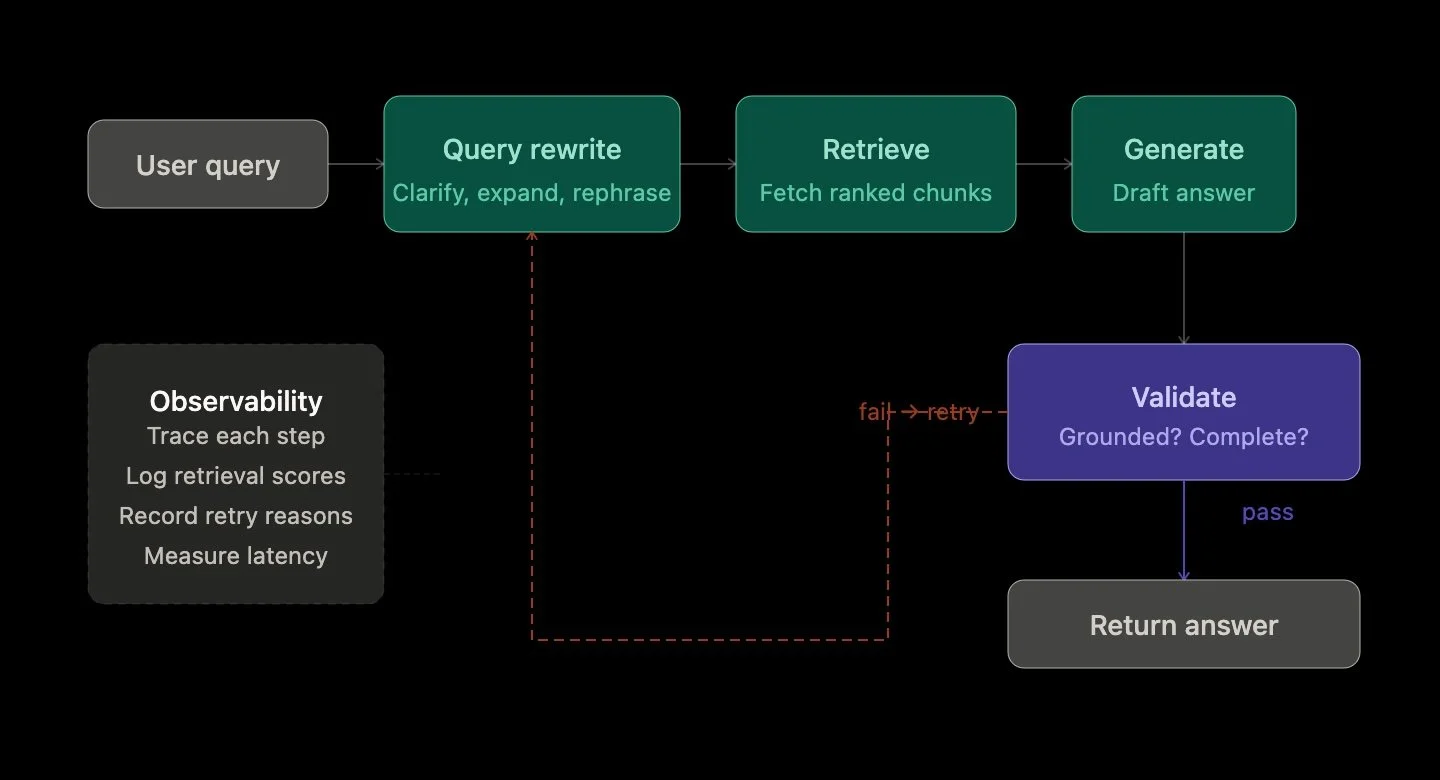
That’s where Agentic RAG comes in. Instead of a single-pass pipeline—retrieve, then generate—you introduce decision-making into the loop. The system can rewrite a query, retrieve again, validate an answer, or even decide that it needs more context before responding. The shift is subtle but important: from a static pipeline to a system that can reason about its own process
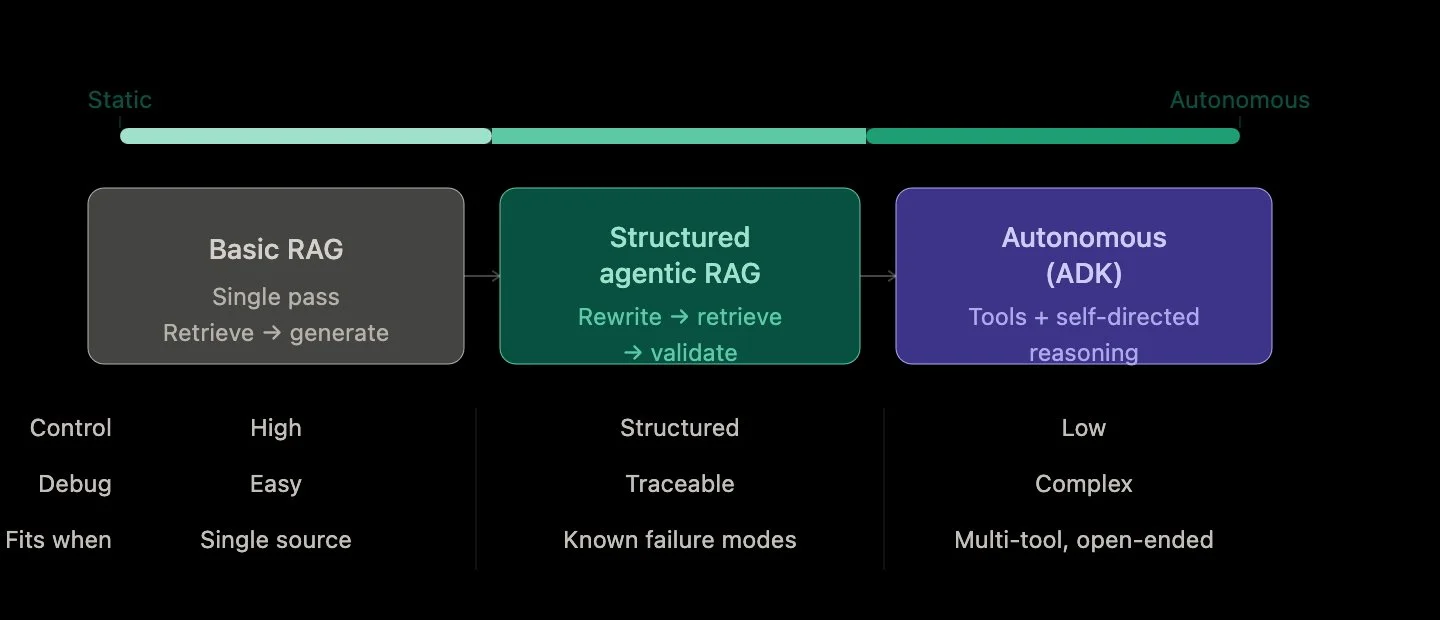
There are two main ways to approach this evolution. The first is structured orchestration—think deterministic flows where each step is clearly defined: rewrite → retrieve → generate → validate. This approach is predictable, debuggable, and works well when paired with strong observability. You can trace exactly what happened at each stage, understand failure points, and iteratively improve the system.
The second path is more autonomous. This is where frameworks like an Agent Development Kit (ADK) come into play. Instead of explicitly defining the flow, you give the system tools and let it decide what to do next. It can choose when to retrieve, when to call an external API, or when to refine its reasoning. This flexibility is powerful, especially for open-ended tasks or multi-tool environments.
But that flexibility comes at a cost. Autonomous systems are harder to debug, harder to control, and often harder to explain. If your use case is a single-source RAG system—like querying a document corpus—introducing a full agent framework can add unnecessary complexity. In many cases, the biggest gains come not from autonomy, but from better structure: improving retrieval, adding query rewriting, and validating outputs.
In my own RAG system, I found that the most impactful improvements came before introducing any agent framework. Separating retrieval and generation into distinct steps, adding trace-level observability, and experimenting with query refinement provided immediate clarity into how the system behaved. Only after that foundation was in place did it make sense to consider more agentic patterns.
This leads to a broader insight: the transition to Agentic RAG isn’t really about adding agents—it’s about deciding when your system needs to think. Not every RAG system does. But when it does, the goal shouldn’t be maximum autonomy. It should be controlled, observable reasoning that improves outcomes without sacrificing reliability.
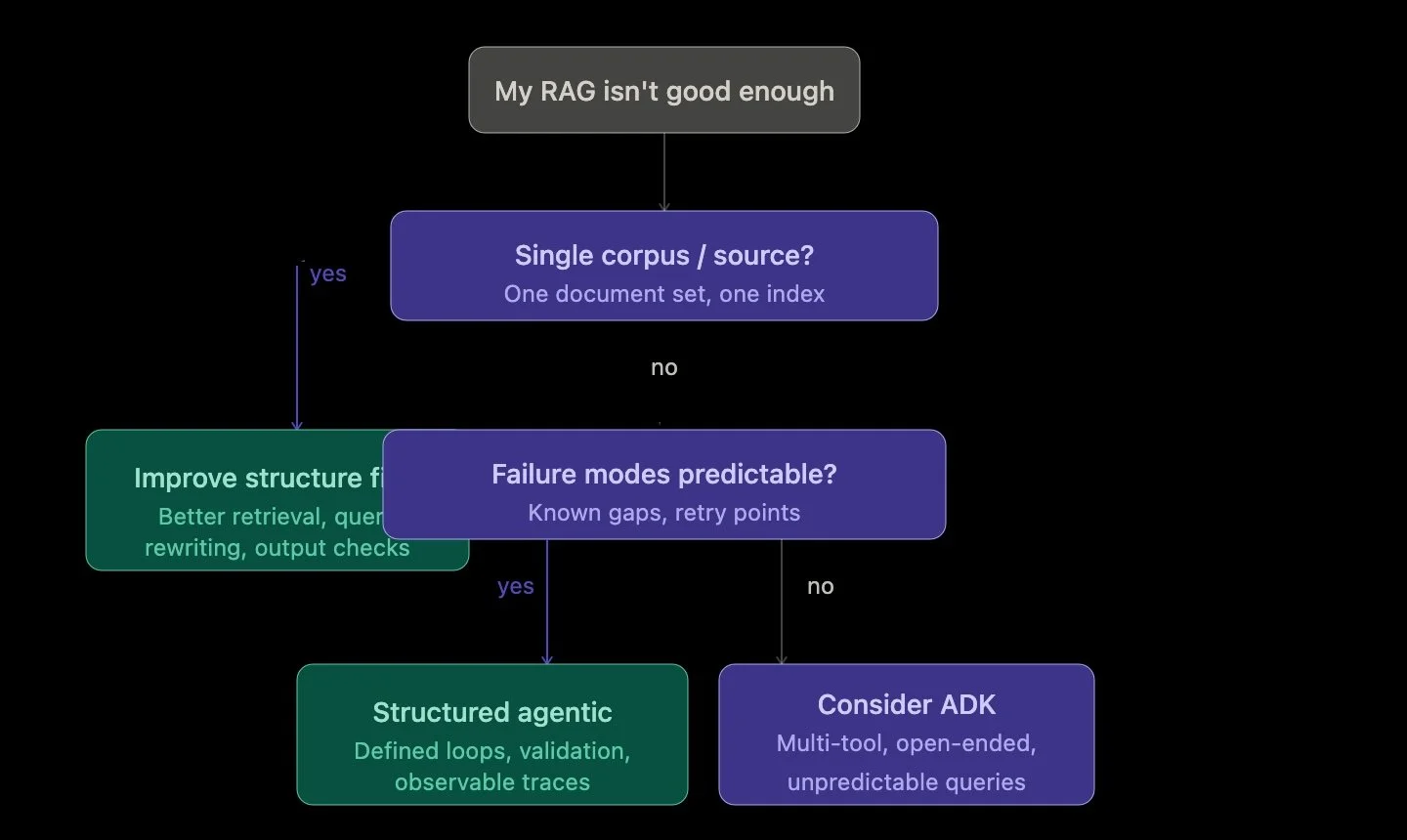
And that’s where ADK fits best—not as a starting point, but as an extension. When your system grows beyond a single workflow, when it needs to coordinate multiple tools or operate in less predictable environments, that’s when autonomy becomes valuable. Until then, structured agentic patterns can take you surprisingly far.
As RAG systems evolve, observability becomes just as important as capability. Once you introduce loops, retries, and decisions, you need to understand not just what the system answered, but how it got there. That’s the real challenge—and the real opportunity—in building agentic AI systems.