Mixture of Experts (MoE)
Mixture of Experts (MoE) is a neural network architecture that routes each input to only a subset of “expert” models rather than using the entire model for every computation. A gating network decides which experts to activate, making MoE models highly efficient and scalable because they increase parameter count without increasing compute proportionally. For example, Google’s Switch Transformer, OpenAI’s Gated MoE layers, and Meta’s LLaMA MoE variants all use expert routing to achieve large-model performance with significantly lower computational cost.
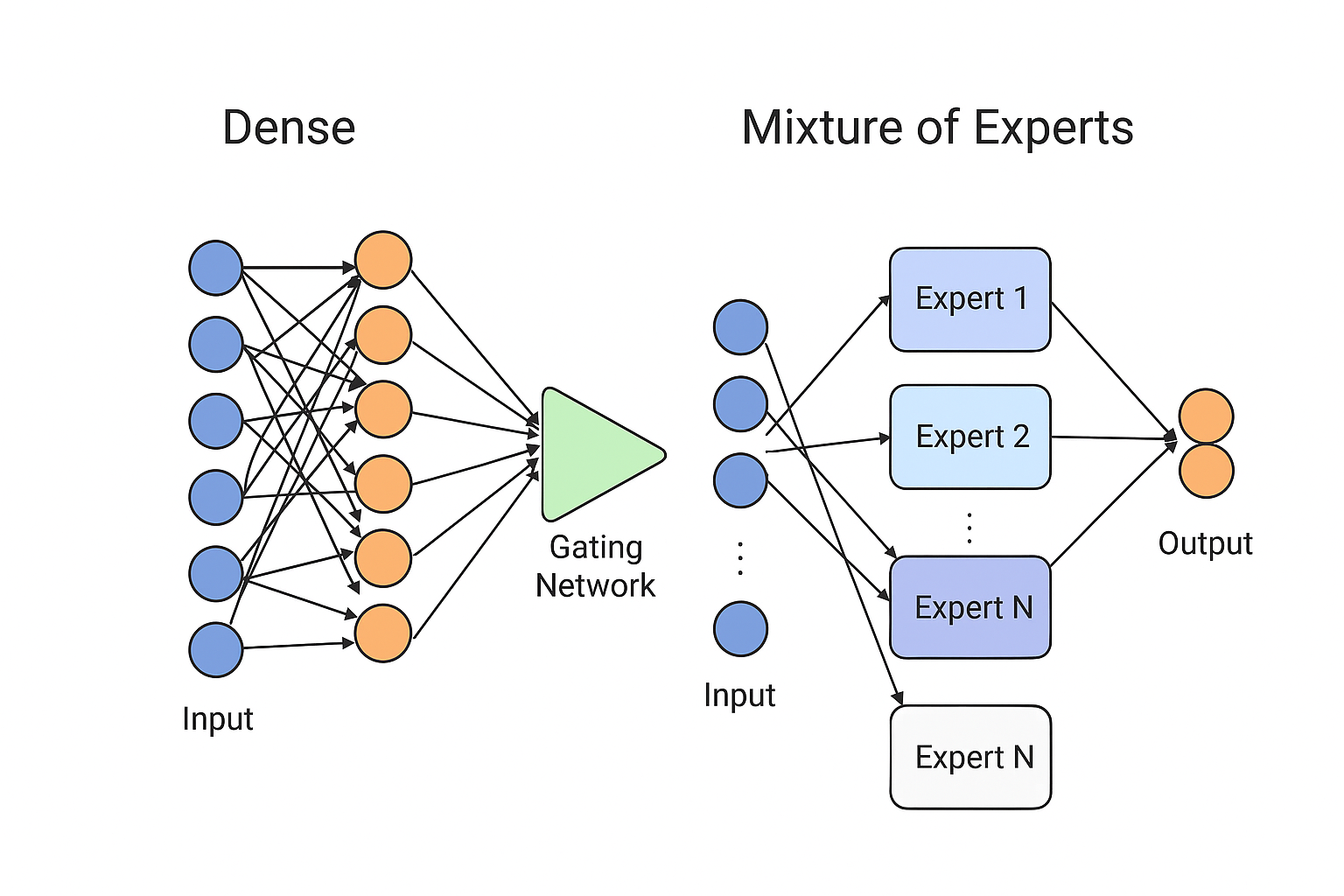
Neural Network vs. MoE Comparison