From Outputs to Systems: Rethinking RAG Evaluation with Observability
Retrieval-Augmented Generation (RAG) systems are often evaluated using familiar patterns from traditional machine learning: measure accuracy, compare outputs to expected answers, and optimize for better scores. This approach works well for static models, where behavior is relatively predictable. But RAG systems are fundamentally different. They are composed systems involving retrieval, ranking, prompt construction, and generation — each contributing to the final outcome. Evaluating only the output assumes the system behaves as a single unit, when in reality it operates as a chain of interdependent components.
This creates a critical blind spot. A system can produce a correct answer for the wrong reasons — retrieving irrelevant documents but generating a plausible response. Conversely, it can retrieve the right information but fail to use it effectively. Output-based evaluation cannot distinguish between these scenarios. Without visibility into intermediate steps, teams are left guessing where issues originate. Evaluation, in this form, becomes reactive and imprecise, limiting the ability to systematically improve system behavior.
The challenge becomes more pronounced in production environments, where RAG systems operate under constant change. Data sources evolve, embeddings are updated, and user queries vary in unpredictable ways. What works in offline testing may degrade over time without clear signals. Unlike traditional evaluation setups based on static datasets, RAG systems require continuous validation against a moving target. This makes evaluation not just a one-time activity, but an ongoing process tied to how the system behaves in real-world conditions.
There is also a mismatch between what is measured and what actually matters. Metrics such as exact match or semantic similarity capture correctness at a surface level, but fail to reflect usefulness, relevance, or grounding in retrieved data. A response may be technically correct yet incomplete, misleading, or disconnected from its sources. Optimizing for these metrics can improve scores without improving outcomes, creating a gap between evaluation results and user experience.
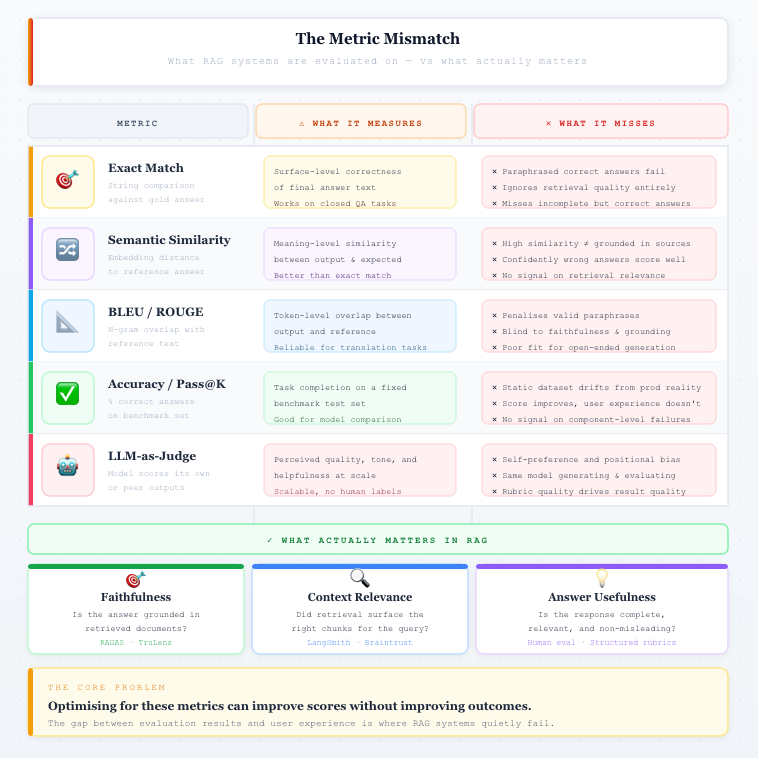
The Metric Mismatch
To address this, evaluation needs to evolve from output-focused measurement to system-level understanding. Instead of asking only “Is the answer correct?”, teams should ask: “Did the system retrieve the right information?”, “Did it use that information appropriately?”, and “How did it arrive at this result?” Answering these questions requires visibility into the system’s internal steps — making retrieval, prompt construction, and decision flow observable and measurable.
This is where observability becomes essential. By integrating evaluation with observability, teams can move beyond black-box assessment and begin to understand how their systems behave. Platforms like LangSmith and Braintrust are emerging to support this shift, enabling tracing, structured evaluation workflows, and deeper insight into system execution. These capabilities make it possible to connect outcomes with the processes that produced them.
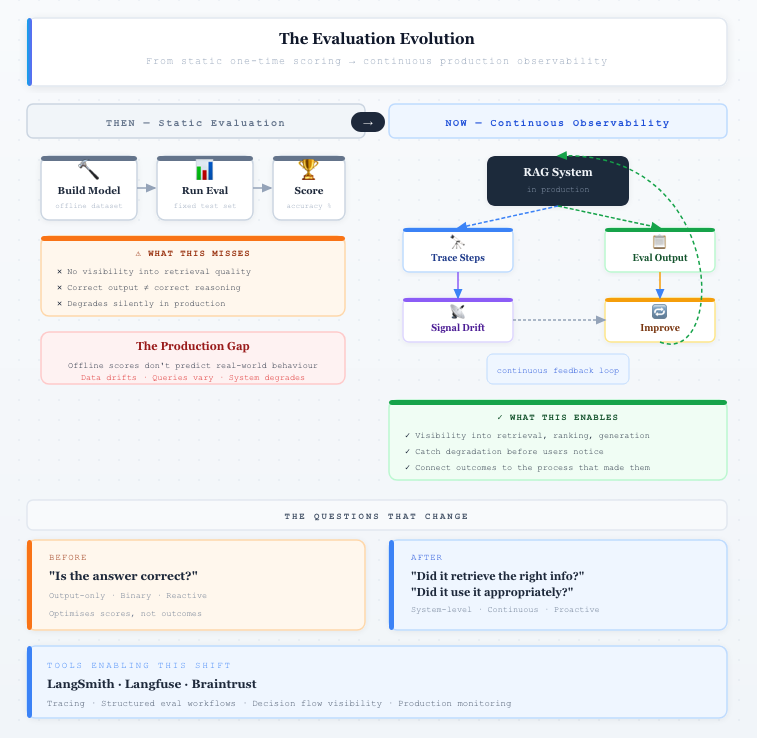
The Evaluation Evolution
However, tooling alone is not enough. The real shift is conceptual: treating RAG not as a model to be scored, but as a system to be continuously observed, evaluated, and improved. Evaluation is no longer a standalone step — it is part of how AI systems are understood and operated in production. Moving from outputs to systems is not just a technical adjustment; it is a necessary evolution for building reliable, trustworthy AI.