The Next Evolution of RAG: Agentic Retrieval Systems
Retrieval-Augmented Generation (RAG) quickly became the default architecture for enterprise AI systems. By combining LLMs with vector databases, teams could ground responses in proprietary knowledge. But as organizations deploy RAG at scale, new limitations are emerging: stale embeddings, noisy retrieval results, and growing security risks when sensitive data is centralized.
A new pattern is emerging in production systems: agentic retrieval architectures. Instead of retrieving context first and then invoking the model, intelligent agents dynamically decide what information they need and retrieve it in real time. These agents can query APIs, search internal tools, and interact with databases as part of a broader workflow.
Protocols like the Model Context Protocol (MCP) are accelerating this shift by standardizing how AI models access external systems. Rather than embedding all knowledge into a vector store, MCP allows agents to retrieve data directly from source systems — preserving existing access controls and reducing the risk of context poisoning or stale information.
In practice, modern AI systems increasingly combine RAG, tools, and multi-agent orchestration. Retrieval becomes just one capability within a broader agent ecosystem that can reason, query systems, and execute actions. For engineering teams building production AI, the challenge is no longer just building better RAG pipelines — it’s designing reliable agent architectures that can retrieve, verify, and act on information safely.
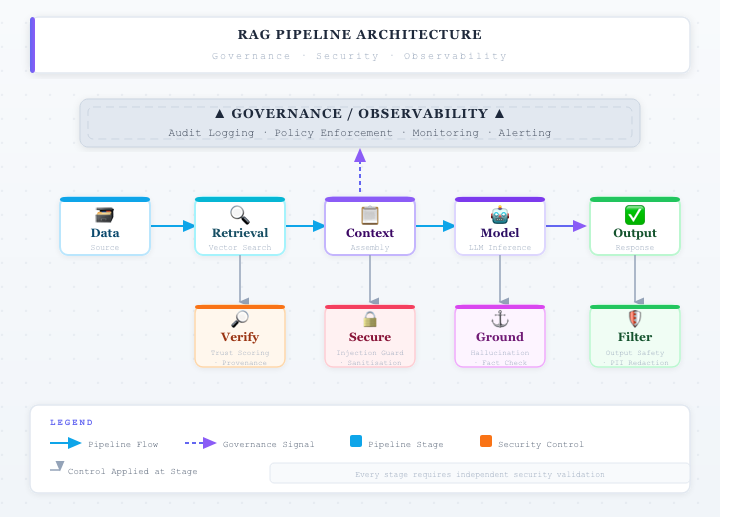
Verification Layers of Production RAG Systems