How to Defend Against RAG Data Poisoning: A Production Playbook
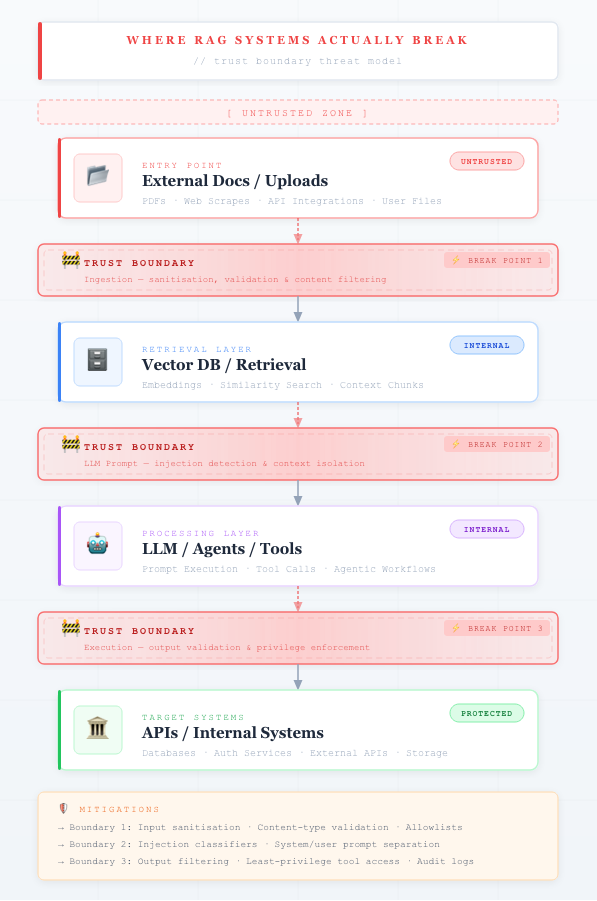
As Retrieval-Augmented Generation (RAG) systems move from prototypes into production, a new class of security risks is emerging. One of the most critical is data poisoning in the retrieval layer—where malicious or untrusted content is ingested into the system and later retrieved as part of the model’s context. Unlike traditional attacks that target the model itself, RAG poisoning exploits the fact that language models inherently trust the data they are given. If compromised data enters the pipeline, the model can be manipulated into producing misleading, unsafe, or even harmful outputs.
The first line of defense is controlling the ingestion pipeline. Many organizations automatically index documents from shared storage systems such as Amazon S3, internal knowledge bases, or collaboration tools. Without strict controls, these sources can become entry points for malicious content. Production systems should enforce source allowlists, document provenance tracking, and content scanning before indexing. Treat ingestion as a security boundary: every document entering the system should be validated, classified, and, where necessary, sanitized before being embedded.
The second layer focuses on retrieval-time filtering and context validation. Even with strong ingestion controls, not all risks can be eliminated upstream. At retrieval time, systems should evaluate whether documents contain prompt injection patterns, hidden instructions, or anomalous content. Techniques such as semantic filtering, anomaly detection, and rule-based scanning can reduce the likelihood that unsafe content is passed into the model’s prompt. This effectively turns retrieval into an active security checkpoint, rather than a passive data lookup.
Beyond retrieval, modern systems are increasingly adopting verification layers to validate model outputs. In a common pattern, a second model evaluates whether the generated response is grounded in trusted sources and free from policy violations. This dual-model verification approach helps detect when poisoned context has influenced the output. Some organizations extend this further with policy enforcement layers that check for data leakage, unsafe instructions, or compliance violations before responses are delivered to users. These controls transform RAG systems into self-checking pipelines rather than single-pass generators.
Another critical component is tool and execution isolation, especially in agent-based architectures. If a model can call APIs, query databases, or trigger workflows, poisoned context may lead to unintended actions. To mitigate this, execution environments should enforce strict permissions, input validation, and sandboxing. The model should never have direct, unrestricted access to sensitive systems. Instead, all actions should pass through controlled interfaces that validate intent and enforce policy constraints.
RAG Breakage
Ultimately, defending against RAG data poisoning requires a shift in mindset. Reliability and security are no longer properties of the model alone—they are properties of the entire system architecture. The most effective production systems implement layered defenses across ingestion, retrieval, generation, and governance. As AI systems become more deeply integrated with enterprise data and workflows, success will depend on treating RAG not just as a retrieval technique, but as a secure knowledge processing pipeline with built-in verification and control.