From RAG to Agentic RAG: Where ADK Fits (and Where It Doesn’t)
Retrieval-Augmented Generation (RAG) has quickly become a foundational pattern for building AI systems that ground responses in real data. And it works—up to a point. But anyone who has spent time building a RAG system knows where it starts to break down: vague user queries, incomplete retrieval, and no mechanism to recover when the first answer isn’t good enough. The limitation isn’t just the model or the data. It’s the lack of iteration.
That’s where Agentic RAG comes in. Instead of a single-pass pipeline—retrieve, then generate—you introduce decision-making into the loop. The system can rewrite a query, retrieve again, validate an answer, or even decide that it needs more context before responding. The shift is subtle but important: from a static pipeline to a system that can reason about its own process
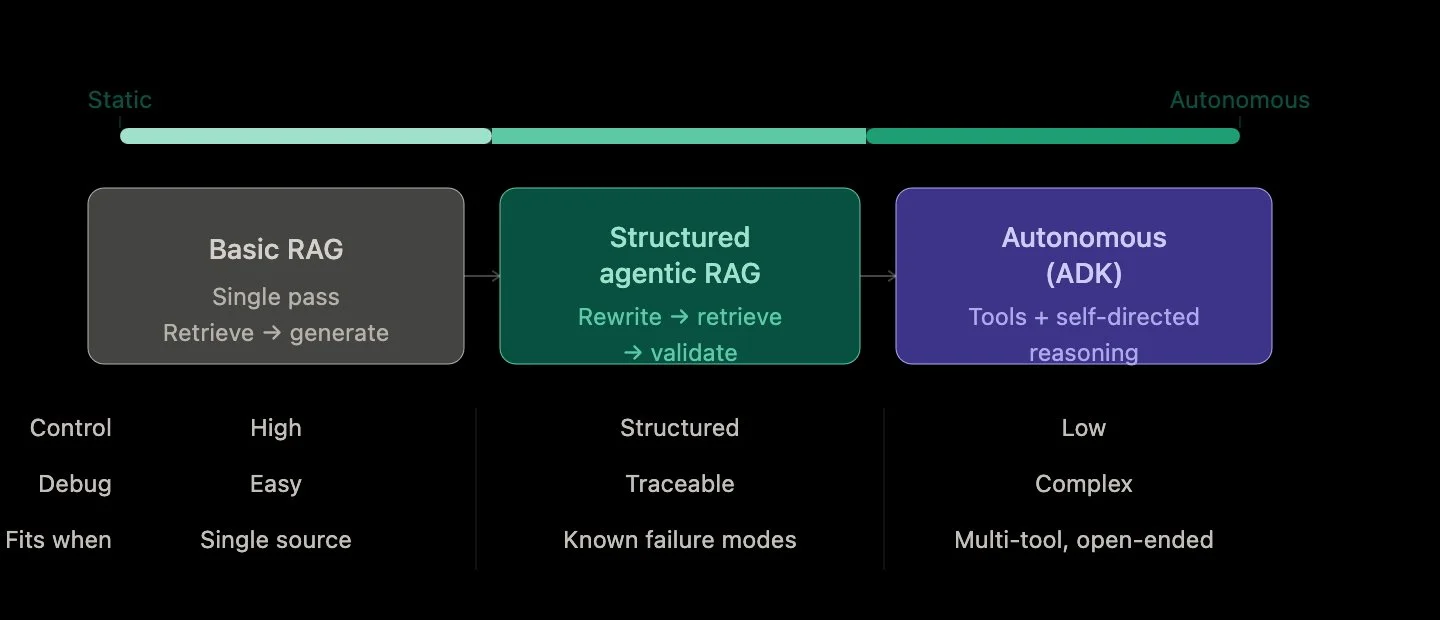
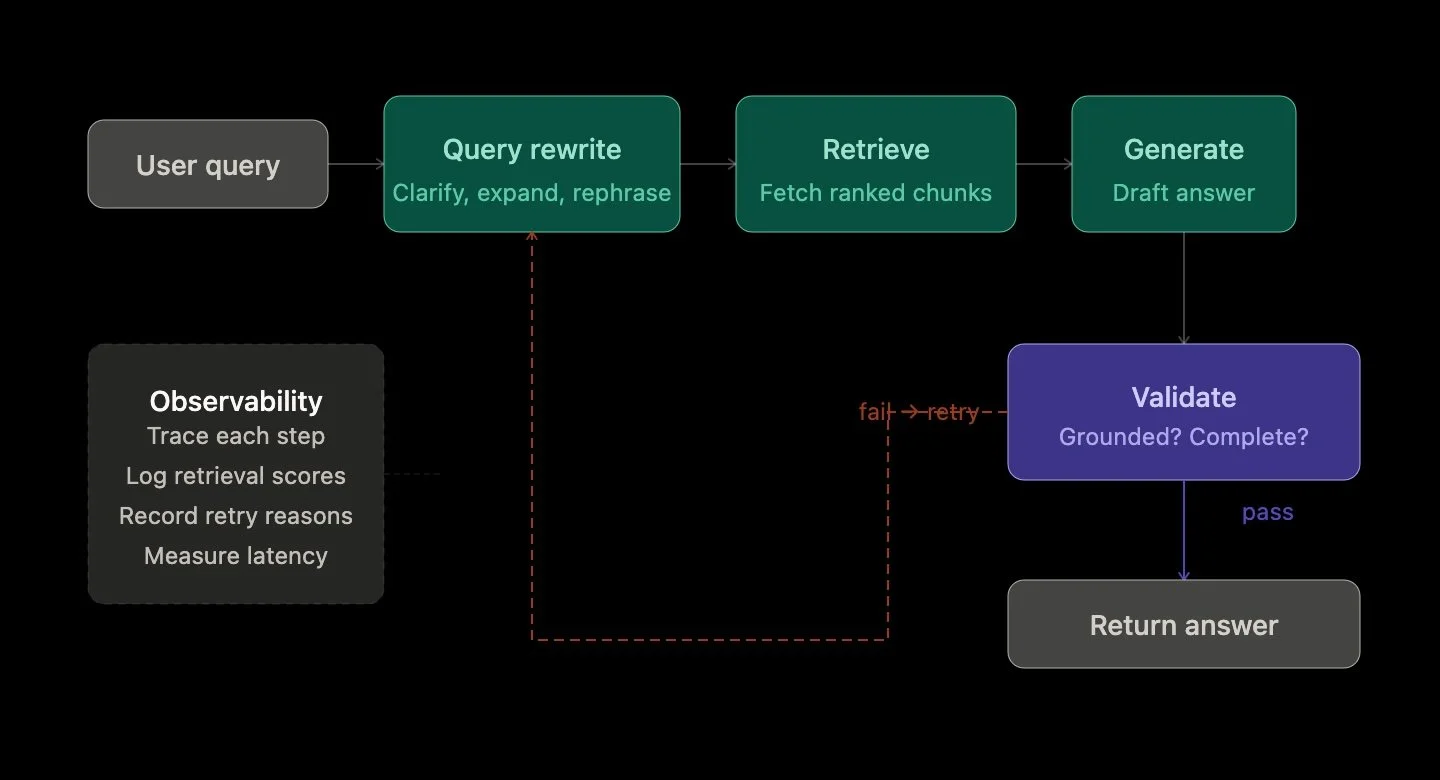
There are two main ways to approach this evolution. The first is structured orchestration—think deterministic flows where each step is clearly defined: rewrite → retrieve → generate → validate. This approach is predictable, debuggable, and works well when paired with strong observability. You can trace exactly what happened at each stage, understand failure points, and iteratively improve the system.
The second path is more autonomous. This is where frameworks like an Agent Development Kit (ADK) come into play. Instead of explicitly defining the flow, you give the system tools and let it decide what to do next. It can choose when to retrieve, when to call an external API, or when to refine its reasoning. This flexibility is powerful, especially for open-ended tasks or multi-tool environments.
But that flexibility comes at a cost. Autonomous systems are harder to debug, harder to control, and often harder to explain. If your use case is a single-source RAG system—like querying a document corpus—introducing a full agent framework can add unnecessary complexity. In many cases, the biggest gains come not from autonomy, but from better structure: improving retrieval, adding query rewriting, and validating outputs.
In my own RAG system, I found that the most impactful improvements came before introducing any agent framework. Separating retrieval and generation into distinct steps, adding trace-level observability, and experimenting with query refinement provided immediate clarity into how the system behaved. Only after that foundation was in place did it make sense to consider more agentic patterns.
This leads to a broader insight: the transition to Agentic RAG isn’t really about adding agents—it’s about deciding when your system needs to think. Not every RAG system does. But when it does, the goal shouldn’t be maximum autonomy. It should be controlled, observable reasoning that improves outcomes without sacrificing reliability.
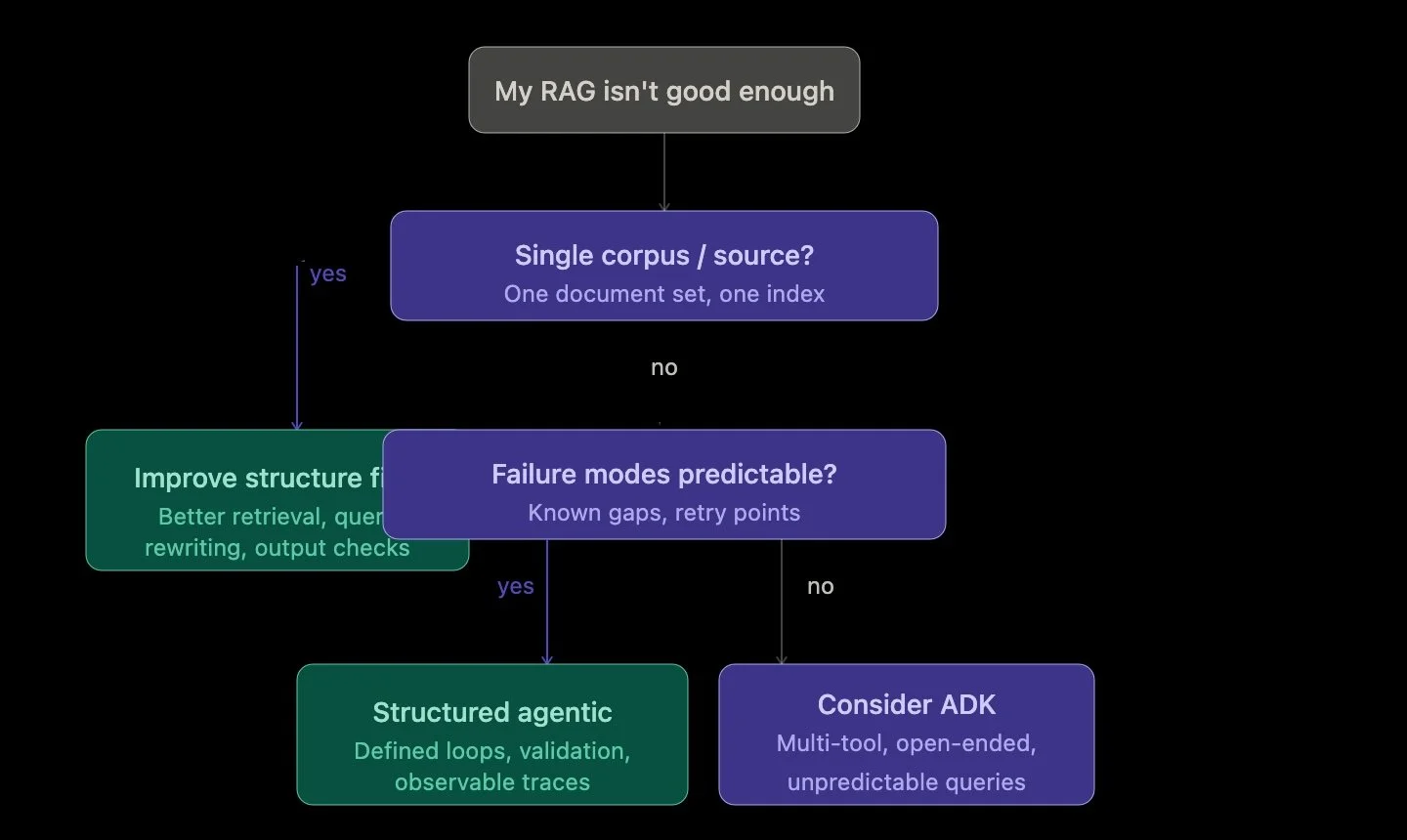
And that’s where ADK fits best—not as a starting point, but as an extension. When your system grows beyond a single workflow, when it needs to coordinate multiple tools or operate in less predictable environments, that’s when autonomy becomes valuable. Until then, structured agentic patterns can take you surprisingly far.
As RAG systems evolve, observability becomes just as important as capability. Once you introduce loops, retries, and decisions, you need to understand not just what the system answered, but how it got there. That’s the real challenge—and the real opportunity—in building agentic AI systems.